Szybkie wprowadzenie do Apache Kafka
Jedno z pierwszych pytań otwartych na prowadzonym przez nas szkoleniu to "Czym jest Apache Kafka?", doskonale pokazuje, że najtrudniejsze są odpowiedzi na proste pytania. Najczęściej wyobrażenie kursantów o Apache Kafka orbituje w około "kolejka wiadomości", "RabbitMQ na sterydach" lub "szyna danych". Każda z tych odpowiedzi ma ziarno prawdy, ponieważ bazując na Apache Kafka możemy w łatwy sposób zaimplementować popularny wzorzec Publisher-Subscriber które jest również realizowany przez obecnie najpopularniejszy na świecie pośrednik wymiany wiadomości czyli RabbitMQ.
Posiłkując się oficjalnymi materiałami Apache Kafka to:
Apache Kafka is an open-source distributed event streaming platform used by
thousands of companies for high-performance data pipelines, streaming analytics,
data integration, and mission-critical applications.
Apache Kafka to rozproszona plaforma strumieniowania zdarzeń typu Open Source wykorzystywana przez tysiące firm do wysoko wydajnego przetwarzania strumieni danych, analityki, integracji danych oraz aplikacji krytycznych.
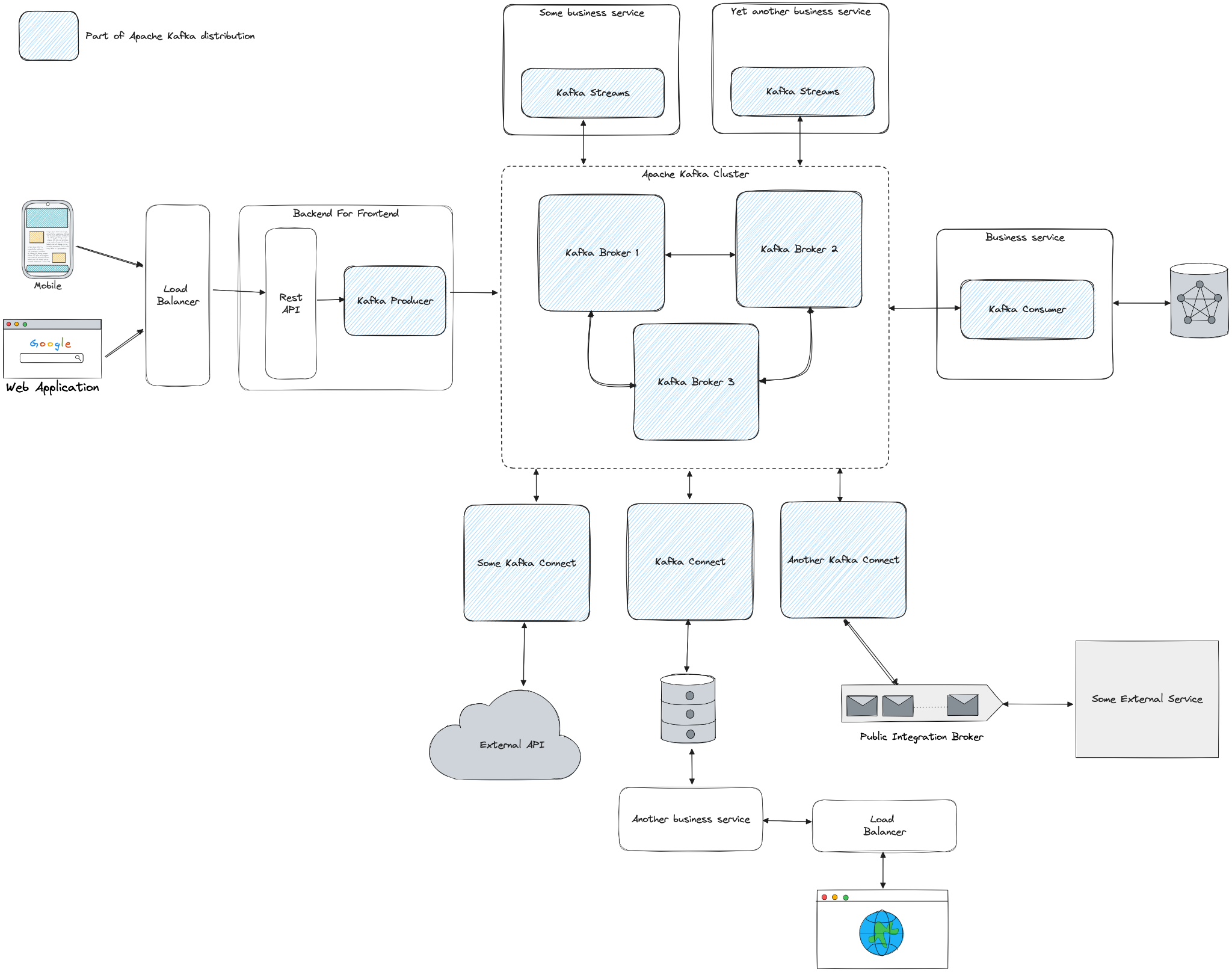
z czego składa się Apache Kafka?
- Kafka Broker
- Kafka Producer
- Kafka Consumer
- Kafka Streams
- Kafka Connect
Wymienione komponenty tworzą platformę dzięki której możemy w czasie rzeczywistym przetwarzać dane. Skupmy się teraz na tym
jak współpracują komponenty platformy Apache Kafka?

W centrum diagramu znajduje się serce platformy czyli Kafka Broker. Jest to komponent który odpowiada za zapis wiadomości na dysku. Najczęściej Kafka Broker łączy się z innymi instancjami Kafka Broker tworząc klaster. Najbardziej znanym i szeroko wykorzystywanym odpowiednikiem Kafka Broker w świecie systemów informatycznych jest po prostu baza danych (relacyjna, dokumentowa itp.)
Omówiliśmy już centrum diagramu, wiemy gdzie przechowywane są wiadomości, przejdźmy teraz w lewo i na dół. Znajdują się tam dwa komponenty: Kafka Producer i Kafka Connect, ich odpowiedzialnością jest dostarczenie danych do brokera Kafka.
Kafka Producer jest to biblioteka Java, sterownik implementujący specyfikację protokołu komunikacyjnego Apache Kafka. Odnosząc się do świata baz danych Kafka Producer można porównać do dowolnego sterownika bazodanowego, przykładowo pgJDBC.
O ile wspomniany przed chwilą Kafka Producer ma dokładnie jedną odpowiedzialność, tak Kafka Connect odpowiada za dostarczenie danych do Kafka Broker oraz eksport danych poza Kafkę, skupmy się teraz na pierwszej części. Kafka Connect jest narzędziem integracyjnym łączącym się jednocześnie z dowolnym, wskazanym w konfiguracji źródłem danych (baza danych, pliki, inny system kolejkowy itp.) oraz z Kafka Brokerem. Kafka Connect w sposób ciągły odczytuje zmiany jakie wykonały się po stronie źródła danych (przykładowo pojawia się nowy plik na zasobie sieciowym) i zapisuje te zmiany na Kafce. W tym przypadku znalezienie odpowiednika Kafka Connect w świecie baz danych nie jest proste. Z jednej strony Kafka Connect jest podobny do biblioteki Spring Integration, w obydwu przypadkach mamy do czynienia z biblioteką Java definiującą wysokopoziomowy zbiór interfejsów standaryzujących integrację pomiędzy różnymi magazynami danych. Z drugiej strony, rozmawiając o Kafka Connect najczęściej mówimy o zbiorze gotowych do wykorzystania implementacji, które jako użytkownicy tylko konfigurujemy i uruchamiamy (nie piszemy kodu implementującego specyfikację Kafka Connect), i z tej perspektywy Kafka Connect jest raczej podobny do narzędzi eksportujących dane z dowolnego źródła do bazy, przykładowo AWS Database Migration Service (AWS DMS). A więc z jednej strony Kafka Connect jest podobny do Spring Integration - to biblioteka Java zawierająca zbiór wysokopoziomowych abstrakcji, ale tej części na 99% procent nie będziecie dotykać w trakcie dalszej kariery zawodowej, natomiast na pewno będziecie zainteresowani uruchomieniem jednej z gotowych implementacji, na przykład Debezium integrujące Postgresql lub MongoDB z Apache Kafka.
Przejdźmy do sekcji odpowiadającej za konsumowanie danych z klastra Kafki. Na naszym diagramie przechodzimy w prawo i na dół, znajdujemy tam Kafka Consumer oraz ponownie Kafka Connect.
Kafka Consumer to druga część najbardziej niskopoziomowego, natywnego sterownika Apache Kafka, razem z Kafka Producer pokrywają 100% funkcjonalności zapisu i odczytu danych z Apache Kafka. Podobnie jak w przypadku Producera, Kafka Consumera możemy porównać do sterownika bazodanowego.
Opis narzędzia Kafka Connect z poprzedniego paragrafu jest również odpowiedni w kontekście konsumowania wiadomości. W tym jednak przypadku Apache Kafka jest źródłem danych a Kafka Connect odpowiada za wysłanie danych do innych magazynów danych takich jak bazy danych, pliki, magazyny obiektów czy też inne systemu informatyczne udostępniające API.
Pora na przyjrzenie się ostatniemu klockowi z naszego diagramu, części odpowiadającej za wydajne przetwarzanie strumieni danych oraz analityki. Do wykonania tych operacji dystrybucja Apache Kafka dostarcza komponent znajdujący się na górze diagramu - Kafka Streams. Jest to biblioteka Java dostarczająca szereg wysokopoziomowych interfejsów za pomocą których w sposób deklaratywny definiujemy strumienie danych i operacje jakie mają być na nich wykonane. Biblioteka wykorzystuje do tego omówione wcześniej podstawowe wersje sterownika Kafka Consumer oraz Kafka Producer, jednak w odróżnieniu imperatywnego modelu programowania narzuconego przez te sterowniki, w Kafka Streams wykorzystujemy deklaratywny model programowania, to znaczy nie piszemy już pętli czy kodu odpowiadającego sterowanie a jedynie deklarujemy co ma się wydarzyć ze zdefiniowanym przez nas strumieniem danych, przykład:

Na koniec diagram obrazujących wykorzystanie platformy Apache Kafka w otoczeniu innych szeroko wykorzystywanych w tworzeniu aplikacji biznesowych komponentów takich jak Rest API czy bazy danych.
Zostaw komentarz